Data access APIs
Overview
Genesis data access APIs provide access to the data in a Genesis application. They are used by most of the server capabilities to enable an application to write, read and subscribe to data updates. You can use these APIs when you configure server capabilities, such as the Event Handler, which is used for core business logic. You can also inject the APIs into any application for use in custom modules and processes.
There are several versions of EntityDb API, which enable you to write to and query the data in your database. With the exception of RxDb, they are powered by type-safe entities for tables. These are DAOs generated at build time, based on the data model you have defined.
The versions of the entity EntityDb are:
| API | Languages | Description |
|---|---|---|
SyncEntityDb | Kotlin + Java | A blocking API, simplest to use and helpful when performance isn't critical |
AsyncEntityDb | Kotlin only | An asynchronous API powered by Kotlin coroutines |
RxEntityDb | Java only | An asynchronous API powered by RxJava |
RxDb | Kotlin + Java | An asynchronous API powered by RxJava, which does NOT use type-safe entities |
The difference between blocking (synchronous) and asynchronous is that the code needs to wait on results to occur before moving on.
- In blocking code, the thread will block until the database responds. This code is easier to write and think about logically.
- In async code, the thread will not block: instead, it resumes after the database responds. This is more difficult to write and comprehend, but it can handle more requests concurrently.
All the APIs implement the same methods for reading and writing, but their return types differ and need handling differently in code.
Access control
User access control is not implemented in the API, so the database APIs are not aware of the user accessing them. User-facing capabilities such as query(Data Server), requestReply (Request Server) and eventHandler (Event Handler) all apply access control measures over their DB API interactions. When writing custom code that is writing or reading data for given users, you should apply the same before return read results, or attempting any writes.
Data types
Data types are essential when using the EntityDb APIs. The objects and classes encapsulate the data within your Genesis application and are generated at DAO build time.
Table entities
Table entities are type-safe classes generated by Genesis, which match the application’s tables. The generated entity name is based on the table name, but will be camel case.
For example, TABLE_NAME becomes TableName.
These entities are available for use in all Entity APIs (except RxDb).
All table entities come with builders to help construct these objects.
- In Kotlin, the builder works as a lambda in which the field values are set, and the object is built after the lambda call is completed.
- In Java, the builder is a fluent interface, where fields are set and the object is built in a final
buildcall.
Just before the object is built, the object is validated to make sure all the required fields are set.
The following example shows how the table Trade from the example data model is built:
- Kotlin
- Java
val trade = Trade {
tradeId = 1
tradePrice = 2.1
direction = Direction.BUY
quantity = 500
tradeDate = DateTime.now()
}
Trade trade = Trade.builder()
.setTradeId(1)
.setTradePrice(2.1)
.setDirection(Direction.BUY)
.setQuantity(500)
.setTradeDate(DateTime.now())
.build();
When a table is audited, such as the example TRADE table above, the entity can be easily converted to its audited counterpart by calling the toAuditEntity function.
- Kotlin
- Java
val tradeAudit = trade.toAuditEntity(
auditEventType = "trade modify"
auditEventDatetime = DateTime.now(),
auditEventText = "trade was modified in event",
auditEventUser = user,
)
TradeAudit = trade.toAuditEntity(
"trade modify"
DateTime.now(),
"trade was modified in event",
user
);
View entities
View entities are type-safe classes generated by Genesis to match the views defined in your application's data model. The generated entity name is based on the view name, but will be camel case.
For example, VIEW_NAME becomes ViewName.
These entities are available for use in all Entity APIs (except RxDb).
There are two types of view entity:
- SingleCardinalityViewEntity : all joins are one-to-one
- MultiCardinalityViewEntity : contains one or more joins, which are one-to-many
Index entities
Index entities are nested in table entities and view entities. The name will be based on the index name defined. The entity can be constructed by passing in the field values in order. The first field of the index must always be provided, and the others are optional.
byPrimaryKey() will return an entity for the primary key. Additionally, for each index, there will be a by...() call where ... is the index name.
A unique index entity will only be created when all fields of a unique index are supplied. In all other cases, a non-unique index entity will be created.
View entities inherit the indices of the root table of the view, so with reference to our example data model, the view will also have an index entity for the trade's primary key and indices:
- ById
- ByCounterpartyId
- ByInstrumentId
- ByDate
Entity logging
By default, table and view entities add new lines to the toString() method.
This can help when looking through log files, as each property has a line to itself.
However, in larger projects, and when using tools like grep and log aggregators, this can make the log files harder to manage; as a single log entry can span many lines.
For this, the platform exposes a property in the gradle build script to generate toString() methods that return a String representation of the entity on a single line. To enable this, add generateCompactToString = true to the build.gradle.kts files in each of the genesis-generated-dao and genesis-generated-view modules:
description = "genesis-generated-dao"
codeGen {
// could contain other properties..
generateCompactToString = true
}
Database entities
DbEntity is the common interface implemented by table entities and view entities.
Database records
DbRecord is the most raw representation of a table. It enables you to build a record of a specified table using strings for table, field and index names. It is not type-safe, and is not a recommended method.
The objects cannot be used with entity Db APIs.
Entity Db API
All three entity DB APIs (SyncEntityDb, AsyncEntityDb, RxEntityDb) use the same types and implement the same API methods, with the exception of their return types.
Type convention
| Type | Meaning | Example |
|---|---|---|
E | A table or view entity | Trade |
T | A table entity | Trade |
V | A view entity | TradeView |
EntityIndex<E> | An index of E | Trade.ById |
UniqueEntityIndex<E> | A unique index of E | Trade.ById |
NonUniqueEntityIndex<E> | A non unique index of E | Trade.ByDate |
EntityIndexReference<E> | An index reference of E | Trade.ById |
UniqueEntityIndexReference<E> | A unique index reference of E | Trade.ById |
NonUniqueEntityIndexReference<E> | A non unique index reference of E | Trade.ByDate |
F<E> | The full table /view name for E | TRADE |
Class<E> | The class reference for E | Trade.class |
KClass<E> | The Kotlin class reference for E | Trade::class |
Read operations
get
Get is a simple look-up on the database; it returns a single entity if a match is found, or no records if no match is found.
The following overloads exist for get; fields is a Set<String>.
get(E, EntityIndexReference<E>, fields) : E?get(E, fields) : E?get(E, EntityIndexReference<E>) : E?get(UniqueEntityIndex<E>, fields) : E?get(UniqueEntityIndex<E>) : E?
Syntax
- Kotlin
- Java - RxJava
- Java - Blocking
// we can look up trades by passing in a unique index class:
val trade = db.get(Trade.byId("TRADE_1"))
// a trade object with the primary key set
val trade = db.get(trade)
// a trade object and a reference to unique index
val trade = db.get(trade, Trade.ByTypeId)
// or you can access the index class from the entity
val trade = db.get(trade.byTypeId())
// we can look up trades by passing in a unique index class:
final var trade = db.get(Trade.byId("TRADE_1"))
.blockingGet();
// a trade object with the primary key set
final var trade = db.get(trade)
.blockingGet();
// a trade object and a reference to unique index
final var trade = db.get(trade,Trade.ByTypeId.Companion)
.blockingGet();
// or you can access the index class from the entity
final var trade = db.get(trade.byTypeId())
.blockingGet();
// we can look up trades by passing in a unique index class:
final var trade = db.get(Trade.byId("TRADE_1"))
// a trade object with the primary key set
final var trade = db.get(trade)
// a trade object and a reference to unique index
final var trade = db.get(trade,Trade.ByTypeId.Companion)
// or you can access the index class from the entity
final var trade = db.get(trade.byTypeId())
getAll
This takes multiple unique index class instances and returns the entity type for the record. It takes a List<Pair<String, UniqueEntityIndex<E>>>, where the String is a unique reference to each request.
Overloads
getAll(requestDetails: Flow<Pair<String, UI<E>>): Map<String, E?>getAll(requestDetails: List<Pair<String, UI<E>>): Map<String, E?>
val map = db.getAll(listOf("A" to Trade.byId("TRADE_A"), "B" to Trade.byId("TRADE_B")))
val recordA = map["A"]
val recordB = map["B"]
getAllAsList
This operation is similar to getAll, but takes a List<UniqueEntityIndex<E>>, and returns a List<E?>.
The results are returned in the order they were requested and will be null if no record was found. The result list is guaranteed to be the same count as the input.
Overloads
getAllAsList(Flow<UI<E>>): List<E?>getAllAsList(List<UI<E>>): List<E?>getAllAsList(vararg UI<E>): List<E?>
val list = db.getAllAsList(Trade.byId("TRADE_A"), Trade.byId("TRADE_B"))
val recordA = list[0]
val recordB = list[1]
getByCriteria
getByCriteria is a database operation that supports criteria, sorting and pagination.
Criteria are optional. Where supported, they are pushed down to the underlying database; otherwise, they are evaluated lazily.
Sorting can reference fields or indices and is only supported on SQL databases.
Pagination is supported natively on SQL databases. If criteria are evaluated lazily, pagination is also evaluated lazily.
Derived fields are evaluated only in the application layer, so any criteria on them are evaluated lazily.
Sorting on derived fields is not supported.
getByCriteria is supported from version 8.14.0
Views are fully supported in this operation, including joined tables, only when the system definition SqlViewsEnabled is set to true.
Otherwise, criteria on joined tables are evaluated lazily and sorting by joined fields is not supported.
In this example, we query for a specific instrument.
For easier use in Java, we provide a fluent interface, getByCriteriaBuilder (see more details below).
- Kotlin
- Java
val results: List<Position> = db.getByCriteria<Position>(
criteria = "INSTRUMENT_ID == 'INSTRUMENT_5'"
)
var results = db.getByCriteriaBuilder(Position.class)
.withCriteria("INSTRUMENT_ID == 'INSTRUMENT_5'")
.build();
Database vs lazy evaluation
Where possible, criteria handling and pagination will be offloaded to the database. However, there are a number of cases in which this is not possible, and the criteria will be evaluated lazily. This means that rather than transforming the criteria into an expression the database can handle efficiently, the platform will request all records from the database and will evaluate those criteria in memory. This is not an either/or situation. In cases where the platform is able to partially evaluate the criteria on the database, it will do so. This is called hybrid evaluation.
Lazy evaluation
Lazily evaluated criteria:
- Any criteria on a derived field
- If
SqlViewsEnabledis not true, in views, any criteria on a field on a joined table - If
SqlViewsEnabledis true, in views that use dynamic joins, any criteria on a field on a joined table - On FDB, any criteria that is not a direct index match
Hybrid evaluation
The platform is able to use hybrid evaluation if and only if both database and lazy criteria are combined using &&.
If we have two fields in our criteria, FIELD and DERIVED, where FIELD is a normal field and DERIVED is a derived field, then:
FIELD == 'A' && DERIVED == 'B'=> hybrid evaluation:FIELD == 'A'is evaluated on the database andDERIVED == 'B'is evaluated lazily.FIELD == 'A' || DERIVED == 'B'=> lazy evaluation: bothFIELD == 'A'andDERIVED == 'B'are evaluated lazily.
Parameters
The following parameters are supported. Apart from the table or view, all are optional.
| Parameter | Required | Explanation | Behaviour if not provided |
|---|---|---|---|
| table/view | ✔️ | the table or view | n/a |
| criteria | ❌ | returns rows matching criteria | returns all rows |
| ordering | ❌ | returns rows in order | unsorted |
| paging | ❌ | limits rows by page | returns all rows |
| fields | ❌ | limits fields returned | returns all fields |
Criteria expression
The criteria is a Groovy expression on a table or view row.
-
Expressions use Groovy syntax with a restricted set of operators and methods.
-
Supported literals: strings (single quotes), numbers (ints/decimals), booleans,
null. -
Parentheses for grouping; short-circuit logic with
&&,||; negation with!. -
Supported operators:
- Comparison:
==,!=,>,<,>=,<= - Logical:
&&,||,! - Arithmetic:
+,-,*,/(e.g., inname.substring(name.indexOf(' ') + 1))
- Comparison:
-
Supported String instance methods (field or literal on the left):
contains(String),containsIgnoreCase(String)startsWith(String),endsWith(String)substring(Int),substring(Int, Int),indexOf(String)toLowerCase(),toUpperCase(),trim(),length()
-
Supported
Expr.*helper functions (static):- Text:
Expr.containsIgnoreCase(field, text)Expr.containsWordsStartingWithIgnoreCase(field, text[, delimiterChar])Expr.isNullOrBlank(field),Expr.notNullOrBlank(field)
- Date (accepts
'yyyyMMdd','yyyy-MM-dd','yyyyMMdd-HH:mm:ss', or epochLong):Expr.dateIsToday(fieldOrLiteral)Expr.dateIsAfter(field, date),Expr.dateIsBefore(field, date),Expr.dateIsEqual(field, date)Expr.dateIsGreaterEqual(field, date),Expr.dateIsLessEqual(field, date)
- DateTime (accepts
'yyyyMMdd','yyyy-MM-dd','yyyyMMdd-HH:mm:ss', or epochLong):Expr.dateTimeIsAfter(field, dateTime),Expr.dateTimeIsBefore(field, dateTime)Expr.dateTimeIsGreaterEqual(field, dateTime),Expr.dateTimeIsLessEqual(field, dateTime)Expr.dateTimeIsInRange(field, startInclusive, endInclusive)
- Text:
-
Notes:
- Field names must exist on the target table/view; unknown fields will error during SQL generation.
- Some functions may be normalized into SQL
LIKE, range predicates, or comparisons depending on the backend.
Ordering
- Order by one or more fields using
OrderSpecProvider.fromString("FIELD [ASC|DESC], ..."). - Special values:
PKfor primary key; named indices (for example,POSITION_BY_ID) are expanded to their underlying fields.
- Kotlin
- Java
val ordered = db.getByCriteria<Position>(
ordering = OrderSpecProvider.fromString("QUANTITY, INSTRUMENT_ID DESC")
)
var ordered = db.getByCriteriaBuilder(Position.class)
.withOrdering("QUANTITY, INSTRUMENT_ID DESC")
.build();
Paging
- Page-based paging is supported with SQL backends using
PagingSpec(maxRows, viewNumber). - When
pagingis set and no explicitorderingis provided, the engine orders by primary key for deterministic pagination.
- Kotlin
- Java
val page1 = db.getByCriteria<Position>(
paging = PagingSpec(5, 0)
)
val page2 = db.getByCriteria<Position>(
paging = PagingSpec(5, 1)
)
var page1 = db.getByCriteriaBuilder(Position.class)
.withPage(5, 0)
.build();
var page2 = db.getByCriteriaBuilder(Position.class)
.withPage(5, 1)
.build();
getBulk
This operation creates a Flowable of the whole table.
The records will be sorted in ascending order by the index provided. If no index is provided, they will be sorted by the primary key.
There is also the getBulkFromEnd function, which returns records in descending order.
There are also a number of continuation operations, which return the whole table after the provided record. These methods are deprecated and should not be used going forwards.
Overloads
getBulk<E>(): Flow<E>(Kotlin only)getBulk([Class<E> / KClass<E>]): Flow<E>getBulk(UR<E>): Flow<E>getBulk(UR<E>, fields): Flow<E>getBulk(UR<E>, E, fields): Flow<E>(continuation) (Deprecated)getBulkFromEnd(UR<E>): Flow<E>getBulkFromEnd(UR<E>, E), E: Flow<E>(continuation) (Deprecated)getBulkFromEnd(UR<E>, E, fields), E: Flow<E>(continuation) (Deprecated)getBulkFromEnd(UR<E>, fields): Flow<E>
Syntax
- Kotlin
- Java
// we can pass in Trade as a type parameter
val flow = db.getBulk<Trade>()
// we can pass in the TRADE object
val flow = db.getBulk(TRADE)
// or we can pass in an index reference
val flow = db.getBulk(Trade.ByTypeId)
// we can pass in Trade as a type parameter
final var flowable = db.getBulk(Trade.class);
// we can pass in the TRADE object
final var flowable = db.getBulk(TRADE.INSTANCE);
// or we can pass in an index reference
final var flowable = db.getBulk(Trade.ById.Companion);
getRange
getRange is an operation that can return multiple records from the database.
There are two types of getRange operation:
- single-value range, e.g. trades with CURRENCY set to USD
- interval range, e.g. all trades with TRADE_DATE between 01-Jul-2024 and 01-Aug-2024.
Unlike the get operation, the getRange operation can always return multiple records.
We pass index entities into getRange. When using an interval range, both index entities should be of the same type. in the example below, this is Trade.byDate.
- Kotlin
- Java
// single value
val range = db.getRange(Trade.byCurrency("USD"))
// interval
val range = db.getRange(
Trade.byDate(myStartDate),
Trade.ByDate(myEndDate)
)
// single value
var range = db.getRange(Trade.byCurrencyId("USD"));
// interval
var range = db.getRange(
Trade.byDate(startDate),
Trade.byDate(endDate)
);
Table entities provide methods for building index entities:
- Kotlin
- Java
// single value
val range = getRange(myUsdTrade.byCurrency())
// interval
val range = db.getRange(myStartTrade.byDate(), myEndTrade.byDate())
// single value
var range = getRange(myUsdTrade.byCurrency());
// interval
var range = db.getRange(myStartTrade.byDate(), myEndTrade.byDate());
numKeyFields property
This enables users to query on part of the index. When using the getRange operation, you can tell the database how many fields in the index to use.
By default, all fields are used, but you can override this.
Order matters here; you can get a range on just field 1, on field 1 and field 2, but not on field 2 and field 1.
For example, if on the ORDER table, you have an index on COUNTERPARTY and INSTRUMENT_ID, you could:
- perform a single-value
getRangeoperation onCOUNTERPARTY. For this, setnumKeyFieldsto1. - perform a single-value
getRangeoperation on bothCOUNTERPARTYandINSTRUMENT. For this, setnumKeyFieldsto2.
More examples:
- Kotlin
- Java
// we could look up all rows for both COUNTERPARTY and INSTRUMENT:
val range = db.getRange(myOrder.byCounterpartyAndInstrument())
// which would be equivalent to
val range = db.getRange(myOrder.byCounterpartyAndInstrument(), 2)
// and also
val range = db.getRange(Order.byCounterpartyAndInstrument("CPTY_A", "VOD"))
// or we could look pu by just COUNTERPARTY
val range = db.getRange(myOrder.byCounterpartyAndInstrument(), 1)
// which would be equivalent to
val range = db.getRange(Order.byCounterpartyAndInstrument("CPTY_A"))
// we could look up all rows for both COUNTERPARTY and INSTRUMENT:
var range = db.getRange(myOrder.byCounterpartyAndInstrument());
// which would be equivalent to
var range = db.getRange(myOrder.byCounterpartyAndInstrument(), 2);
// and also
var range = db.getRange(Order.byCounterpartyAndInstrument("CPTY_A", "VOD"));
// or we could look pu by just COUNTERPARTY
var range = db.getRange(myOrder.byCounterpartyAndInstrument(), 1));
// which would be equivalent to
var range = db.getRange(Order.byCounterpartyAndInstrument("CPTY_A"));
numKeyFields is required in the following instances:
- when passing in a table entity and an index reference
- when passing in an index entity that refers to a unique index
Fields
When using a getRange operation, you can provide a Set<String> with the field names you want to select.
This will only be used as a hint; non-nullable fields will always be returned from the database.
- Kotlin
- Java
val range = getRange(
myUsdTrade.byCurrency(),
fields = setOf("PRICE", "QUANTITY")
)
var range = db.getRange(
Trade.byCurrencyId("USD"),
1,
Set.of("PRICE", "QUANTITY")
);
Reversed range look-ups
In addition to getRange there is also the getRangeFromEnd method.
This works in the same way as getRange. However, rows are returned in the reverse order.
Parameters when using index entities
| Name | Type | Required | Meaning | Default value |
|---|---|---|---|---|
| Index | EntityIndex<E> | ✔️, For single value ranges | The index entry to read | |
| Start index | EntityIndex<E> | ✔️, For interval ranges | The index entry to read from | |
| End index | EntityIndex<E> | ✔️, For interval ranges | The index entry to read to | |
| numKeyFields | Int | ❌ | The number of key fields to take into account | All fields in the index |
| fields | Set<String> | ❌ | The names of the fields to return | return all fields |
Write operations
Concepts and helper classes
The entity database will return type-safe results for write operations. There are four main write results, one for each type of write operation. Each of these operations is of type EntityWriteResult.
InsertResult has a single property record which is the inserted record. This includes any generated values.
DeleteResult has a single property record which is the record as it was in the database before it was deleted.
ModifyResult is slightly more complex. It has three properties:
- a
recordproperty, which is the record in the database after the modify operation - a
previousproperty, which is the record as it was before the modify operation - a
modifiedFieldsproperty, which holds aSet<String>of the fields that were changed in the modify
UpsertResult can be either an InsertResult or a ModifyResult.
All write operations have versions that take a single entity and versions that take multiple entities. Different entity types can be inserted in the same operation; however, the return type will be List<InsertResult<Entity>>. Also, modify operations only accept table entities.
Another important helper class is ModifyDetails. It holds details of data modification resulting from a modify or upsert. When performing modify and upsert operations with EntityDb, you must specify the index of the record you wish to perform the operation on. The EntityModifyDetails class enables you to identify the record and the fields to modify.
When writing a record to the database, typically all non-null properties should be set on the entity. An entity property becomes non-nullable if:
- it has a default value
- it is generated by the database, i.e. sequence or auto increment fields
- the column is included in an index or is specifically declared not null in the schema
Default values
Properties with a default value will have the value set by default, unless set explicitly in the builder.
Generated properties
Generated properties are left in an indeterminate state if not set in the builder. When writing to the database, this indeterminate state is set in the return value. Trying to read the property while it is in this state results in an IllegalArgumentException.
Each generated property has only two read-only associated properties to access these properties in a safe manner.
is[FieldName]Generatedboolean property[fieldName]OrNullproperty
For example, where TRADE_ID field on TRADE table is generated:
- Kotlin
- Java
trade.tradeId // will cause an exception if not initialized
trade.tradeIdOrNull // will return the tradeId if set, or else null
trade.isTradeIdInitialised // will return true if set
trade.getTradeId(); // will cause an exception if not initialized
trade.getTradeIdOrNull(); // will return the tradeId if set, or else null
trade.isTradeIdInitialised(); // will return true if set
Columns in indices or are not null explicitly
Columns in indices or declared not null should always be set in a builder, unless it has a default value or is a generated column. In all other instances, a NullPointerException will be thrown when building the object.
insert
This inserts a new record into the database. The insert function takes a single table entity. The insertAll function takes multiple records, and has several overloads:
Overloads
insert(E): InsertResult<E>insertAll(vararg E): List<InsertResult<E>>insertAll(List<E>): List<InsertResult<E>>insertAll(Flow<E>): List<InsertResult<E>>
modify
This tries to modify a record in the database. If the record does not exist, an error is thrown.
Overloads
modify(EntityModifyDetails<E>): ModifyResult<E>modify(E): ModifyResult<E>modify(E, UniqueEntityIndexReference<E>): ModifyResult<E>modifyAll(vararg E): List<ModifyResult<E>>modifyAll(vararg EntityModifyDetails<E>): List<ModifyResult<E>>modifyAll(List<EntityModifyDetails<E>>): List<ModifyResult<E>>modifyAll(Flow<EntityModifyDetails<E>>): List<ModifyResult<E>>
upsert
This tries to modify a record in the database. If the record does not exist, the record is inserted instead.
Overloads
upsert(EntityModifyDetails<E>): UpsertResult<E>upsert(E): UpsertResult<E>upsertAll(vararg E): List<UpsertResult<E>>upsertAll(vararg EntityModifyDetails<E>): List<UpsertResult<E>>upsertAll(List<EntityModifyDetails<E>>): List<UpsertResult<E>>upsertAll(Flow<EntityModifyDetails<E>>): List<UpsertResult<E>>
delete
This tries to delete a record.
Overloads
delete(E): DeleteResult<E>delete(UniqueEntityIndex<E>): DeleteResult<E>deleteAll(vararg E): List<DeleteResult<E>>deleteAll(vararg UniqueEntityIndex<E>): List<DeleteResult<E>>deleteAll(List<E>): List<DeleteResult<E>>deleteAll(Flow<E>): List<DeleteResult<E>>
update
The update operation is a condensed syntax for modifying data in the database. It works by providing a scope and a transformation. The scope could be one of:
updateBy- a unique indexupdateRangeBy- an index rangeupdateAll- a whole table
The transformation is a lambda, where the rows that are in scope are provided one by one. The rows are provided as in the database, and can be modified in place, with the changes applied to the database. All update calls use the safeWriteTransaction and are transactional if the database supports it.
-
In the async entity db, the lambda will be of type
E.() -> Unit. The entity will be the receiver and in the lambda,thiswill refer to the row, which should be modified in place. -
In the rx entity db, the lambda will be of type
Consumer<E>. The lambda will have a single parameter, the entity. Similar to the async version, the row should be modified in place.
In both cases, the full record will be provided, and values can be read as well as updated. The operations return
List<ModifyResult<E>> for updateAll and updateRangeBy methods and ModifyResult<E> for the updateBy operation.
For example:
- Kotlin
- Java
db.updateBy(Trade.byId("xxxxx")) {
price = 15.0
}
db.updateByRange(Trade.byOrderId("xxxx")) {
orderStatus = OrderStatus.CANCELLED
}
db.updateByRange(Trade.byOrderId("xxxx"), Trade.byOrderId("yyyy") {
orderStatus = OrderStatus.CANCELLED
}
db.updateAll<Trade> {
orderStatus = OrderStatus.CANCELLED
}
db.updateBy(Trade.byId("xxx"), trade -> {
trade.setPrice(15.0);
}).blockingGet();
db.updateByRange(Trade.byOrderId("xxxx"), trade -> {
trade.setTradeType(OrderStatus.CANCELLED);
}).blockingGet();
db.updateByRange(Trade.byOrderId("xxxx"), Trade.byOrderId("yyyy"), trade -> {
trade.setTradeType(OrderStatus.CANCELLED);
}).blockingGet();
db.updateAll(Trade.class, trade -> {
trade.setTradeType(OrderStatus.CANCELLED);
}).blockingGet();
recover
The recover operation enables you to insert a document into the database using the record's preset timestamp and ID.
The following recover operations are supported:
recoverrecoverAll
This API must be used with caution. Integrity checks are skipped, so it can leave your Genesis application in a poor state if used incorrectly. Record IDs and timestamps are assumed to be unique.
Transactions
If the underlying database supports transactions, then the entity db provides type-safe access to these. A read transaction will support the same read operations as the entity db, and a write transaction will support the same read and write operations. If a write transaction fails, all operations will be reverted. Subscribe operations are not supported within transactions.
Transactions are supported on database layers: FoundationDb, MS SQL, Oracle and Postgresql.
When code is expected to run on multiple database types, transactions should be used when available. You can use safeReadTransaction and safeWriteTransaction. These run operations in the block in a single transaction, if supported.
There is a distinction between using Kotlin and Java here.
- When using Kotlin, the transaction is the receiver in the
readTransactioncall. This means that within the block,thisrefers to the transaction. - When using Java, the transaction is the first parameter of the lambda.
Read transactions
Read transactions ensure that all read operations are consistent. Intervening writes will not affect reads within the transaction. The return value in the transaction will also be returned from the transaction. For the RxEntityDb, it will be a Single<*>.
- Kotlin
- Java
val orderTrade = db.readTransaction {
val trade = get(Trade.byId("TR_123"))
val order = get(Order.byId(trade.orderId))
buildOrderTrade(order, trade)
}
Single<OrderTrade> orderTrade = db.readTransaction(transaction -> {
final var trade = transaction.get(Trade.byId("TR_123")).blockingGet();
final var order = transaction.get(Order.byId(trade.orderId)).blockingGet();
return buildOrderTrade(order, trade);
});
Write transactions
Write transactions ensure all read and write operations are consistent. If any exception reaches the
transaction level, all writes are rolled back. The writeTransaction will return a Pair<T, List<EntityWriteResult<*>>>,
where T is the value returned in the writeTransaction lambda.
- Kotlin
- Java
val (orderId, writeResults) = db.writeTransaction {
insert(trade)
val orderInsert = insert(order)
orderInsert.record.orderId
}
final var pair = db.writeTransaction(transaction -> {
insert(trade).blockingGet();
final var orderInsert = insert(order).blockingGet();
return orderInsert.getRecord.getOrderId();
}).blockingGet();
final var orderId = pair.getFirst();
final var writeResults = pair.getSecond();
Subscribe operations
Subscribe operations create a subscription to the given table or view. They will be invoked whenever updates occur to the entity they are listening to.
Concepts and helper classes
When database updates are distributed, they are wrapped in helper classes:
Generic record update
Generic records provide a generic way of publishing updates by the database. All updates have the same super type, GenericRecordUpdate, which is a sealed Kotlin class. This means that all instances are guaranteed to be one of the implementation types:
GenericRecordUpdate.InsertGenericRecordUpdate.DeleteGenericRecordUpdate.Modify
All these types have the following properties:
tableName:StringrecordId:Longtimestamp:Longemitter:String?
Additionally, GenericRecordUpdate.Insert and GenericRecordUpdate.Delete also have a record field. Whereas GenericRecordUpdate.Modify has an oldRecord and a newRecord field.
Bulk
Bulk objects are published to listeners of mixed read/subscribe operations. Like Record Update, Bulk is a sealed Kotlin class. It has the following class hierarchy:
BulkBulk.PrimeBulk.Prime.RecordBulk.Prime.Complete
Bulk.UpdateBulk.Update.InsertBulk.Update.DeleteBulk.Update.Modify
A bulk flow always follows this sequence:
- 0 or more
Bulk.Prime.Record - 1
Bulk.Prime.Complete - 0 or more
Bulk.Updatesubtypes
subscribe
The subscribe operation starts a database listener that receives updates to tables or views.
Subscribe parameters
Subscribe supports the following parameters:
| Name | Type | Required | Meaning | Default value |
|---|---|---|---|---|
| Table name | String | ✔️ | The table to subscribe to | n/a |
| fields | Set<String> | ❌ | Only listen to changes on selected fields | listen to all fields |
| delay | Int | ❌ | Group and publish updates every x ms | no grouping |
| subscribeLocally | Boolean | ❌ | When in a cluster, only listen to local updates | false |
| listenerName | String | ❌ | When in a cluster, only listen to local updates | generated name |
Overloads
The rx entity db takes a Class<E>, whereas the async entity db takes a KClass<E>.
Parameters marked with an asterisk(*) are optional.
subscribe([KClass<E> / Class<E>], delay*, fields*, subscribeLocally*): Flow<E>
These functions are available in kotlin only:
subscribe<E>(delay*, fields*, subscribeLocally*): Flow<E>
- Kotlin
- Java
val subscription = launch {
db.subscribe<Trade>()
.collect { update ->
println("Received a trade update! $update")
}
}
final var subscription = db.subscribe(Trade.class)
.subscribe(update -> {
System.out.println("Received a trade update! " + update);
});
bulkSubscribe
The bulkSubscribe operation combines a getBulk and a subscribe call into a single operation.
This is useful when a class needs to read a full table and then receive updates of changes to the underlying table or view.
This operation supports backwards joins for views. This means that it can receive updates on both the
root table and the joined tables. The view needs to support this in the definition, and it must be enabled on the bulkSubscribe call.
Example
- Kotlin
- Java
val bulk = db.bulkSubscribe<Trade>()
var bulk = db.bulkSubscribe(Trade.class);
Parameters
bulkSubscribe supports the following parameters:
| Name | Type | Required | Meaning | Default value |
|---|---|---|---|---|
| Table | Class<E> | ✔️ | The table to subscribe to | |
| Index | UniqueEntityIndexReference<E> | ❌ | The index to sort the getBulk operation by | |
| fields | Set<String> | ❌ | Only listen to changes on selected fields (filters ModifyResult on fields) | listen to all fields |
| delay | Int | ❌ | Batch updates x ms | no batching |
| subscribeLocally | Boolean | ❌ | When in a cluster, only listen to local updates | false |
| backwardJoins | Boolean | ❌ | Subscribe to changes on sub-tables (backwards joins) | false |
| listenerName | String | ❌ | When in a cluster, only listen to local updates | generated name |
Java support
There are many optional parameters for bulk subscribe operations. In Kotlin, this works well in a single method, due to named parameters and default values.
In Java, however, we provide a fluent API to set optional parameters.
The function bulkSubscribeBuilder returns a builder.
Optional parameters can be set with a "with-function", e.g. withDelay(...).
Once all values have been set, the toFlowable() function transforms the builder into a Flowable.
More complex example
- Kotlin
- Java
val bulk = db.bulkSubscribe<Trade>(
fields = setOf("TRADE_DATE"),
delay = 500,
subscribeLocally = false,
index = Trade.ByTypeId,
backwardJoins = true,
)
var bulk = db.bulkSubscribeBuilder(Trade.class)
.withFields(Set.of("TRADE_DATE"))
.withDelay(500)
.withSubscribeLocally(false)
.withIndex(Trade.ByTypeId.Companion)
.withBackwardJoins(true)
.toFlowable();
rangeSubscribe
rangeSubscribe is similar to bulkSubscribe. The rangeSubscribe operation combines a getRange and a subscribe call into a single operation.
This is useful when a class needs to read a range of values from table and then receive updates of changes to the relevant records in the underlying table or view.
This operation supports backwards joins for views. This means that it can receive updates on both the root table and the joined tables. The view needs to support this in the definition, and it must be enabled on the bulkSubscribe call.
Different range options
Like getRange, rangeSubscribe supports single-value and interval ranges.
In addition, range subscribe supports both static and dynamic ranges. See below for details.
Note on Java
Like bulkSubscribe, there are many optional parameters for range subscribe operations. In Kotlin, this works well in a single method, due to named parameters and default values.
In Java however, we provide a fluent API to set optional parameters.
The functions staticRangeSubscribeBuilder and dynamicRangeSubscribeBuilder return a builder.
Optional parameters can be set with a "with-function", e.g. withDelay(...).
Once all values have been set, the toFlowable() function transforms the builder into a Flowable.
Static ranges
By default, ranges are static; they are set at the start of the subscription and not updated afterwards.
- Kotlin
- Java
// single-value range
val range = db.rangeSubscribe(Trade.byCurrencyId("USD))
// interval range
val range = db.rangeSubscribe(
Trade.byDate(startDate),
Trade.byDate(endDate)
)
// single-value range
var range = db.staticRangeSubscribeBuilder(Trade.byCurrencyId("USD"))
.toFlowable();
// interval range
var range = db.staticRangeSubscribeBuilder(
Trade.byDate(startDate),
Trade.byDate(endDate)
)
.toFlowable();
Dynamic ranges
Additionally, rangeSubscribe also supports dynamic ranges. These are ranges that are refreshed either at a specified time, or interval.
This can be useful for long-running subscriptions on dates. For example, you might want to keep an eye on trades booked in the last hour. Unless that range is refreshed, it will fall behind.
In the example below, we have two dynamic ranges.
- The first one filters on a specific date, and is updated at midnight.
- The second one has a 2-hour window, and is updated every 5 minutes.
- Kotlin
- Java
// single-value range
db.rangeSubscribe(
fromProvider = { Trade.byDate(DateTime.now().withTimeAtStartOfDay()) },
updateFrequency = PalDuration.At(LocalTime.MIDNIGHT)
)
// interval range
db.rangeSubscribe(
fromProvider = { Trade.byDate(DateTime.now().minusHours(1)) },
toProvider = { Trade.byDate(DateTime.now().plusHours(1)) },
updateFrequency = PalDuration.Every(Duration.ofMinutes(5))
)
// single-value range
var range = db.dynamicRangeSubscribeBuilder(
() -> Trade.byDate(DateTime.now().withTimeAtStartOfDay())
).withUpdateFrequency(new PalDuration.At(LocalTime.MIDNIGHT))
.toFlowable();
// interval range
var range = db.dynamicRangeSubscribeBuilder(
() -> Trade.byDate(DateTime.now().minusHours(1)),
() -> Trade.byDate(DateTime.now().plusHours(1))
).withUpdateFrequency(new PalDuration.Every(Duration.ofMinutes(5)))
.toFlowable();
Parameters
For static ranges rangeSubscribe supports the parameters below.
In the Java API, the function returns a builder, where optional parameters can be set.
| Name | Type | Required | Meaning | Default value |
|---|---|---|---|---|
| Start index | EntityIndex<E> | ✔️ | The index entry to read from | |
| End index | EntityIndex<E> | For interval ranges | The index entry to read to | |
| numKeyFields | Int | ❌️ | The number of key fields to take into account for the range | |
| updateFrequency | PalDuration | For dynamic ranges | A schedule to update dynamic range boundaries | ? |
| delay | Int | ❌ | Group and publish updates every x ms | 200ms |
| fields | Set<String> | ❌ | Only listen to changes on selected fields (filters ModifyResult on fields) | listen to all fields |
| subscribeLocally | Boolean | ❌ | When in a cluster, only listen to local updates | false |
| backwardJoins | Boolean | ❌ | Subscribe to changes on sub-tables (backwards joins) | false |
| listenerName | String | ❌ | When in a cluster, only listen to local updates | generated name |
Example
- Kotlin
- Java
val range = asyncEntityDb.rangeSubscribe(
from = Trade.byDate(startDate),
to = Trade.byDate(endDate),
numKeyFields = 1,
delay = 500,
fields = emptySet(),
subscribeLocally = true,
backwardJoins = true
)
val range = db.staticRangeSubscribeBuilder(
Trade.byDate(startDate),
Trade.byDate(endDate)
)
.withNumKeyFields(1)
.withDelay(500)
.withFields(Collections.emptySet())
.withSubscribeLocally(true)
.withBackwardJoins(true)
.toFlowable();
Subscribing to views
There are some subtleties when it comes to subscriptions on views.
By default, when subscribing to updates on a view, only updates on the root table are sent. If you want updates on the joined table or tables, you must [enable a backwardsJoin on each join.
Inner joins can produce different results. For example, a modification to a table could become a delete or insert on the view. There are details of inner joins in our page on views.
Overall, the better you understand Data Servers, the better your chances of implementing Entity Db without errors. It is well worth looking through the entire section in our documentation.
Update batching
For subscribe operations, by default, Genesis does not publish every update received. Updates are batched and compressed before publishing. This is designed to reduce the load on high-volume systems.
Batching is controlled by the delay parameter in the subscribe method. This is used to specify the batching interval for updates.
For example, if a trade is inserted, and then modified rapidly in quick succession within the same batching period, there is no requirement for publishing any intermediate states. It is easier and more efficient for the system to publish a single update, so the insert and modify are compressed into a single insert update.
Batching phases
Batching happens in two phases:
- The updates are gathered together.
- At the end of the batching period, they are compressed and the resulting updates are published.
So what does this mean in practice?
The batching period covers the whole subscription. It is always set globally, i.e. for an update queue subscription or on a data server query. It is never set at the individual row level.
The goal of this batching is to minimize work, and to publish updates that are accurate, rather than to publish every change.
In this regard it is better to think in terms of a batching interval, rather than a batching period, which looks something like this:
...
*
|---- gathering phase ----| (batching period)
*
*
*
*
*
|---- flushing phase -----| (commence compress and publish)
* compress updates
* publish updates
|---- gathering phase ----| (next batching period)
*
*
...
Batching is non-deterministic
Batching occurs within discrete batching and only within each period.
- If a trade is inserted and then modified within a single batching period, the two will be compressed into a single update.
- If the trade is inserted one millisecond before the end of a batching period, it is modified right at the start of the next period; the insert is sent at the end of the first period and the update is sent at the end of the next period - there are two updates.
The point here is that there is no way of determining whether a series of updates and modifies will be compressed or not. It is entirely determined by the timing of the individual inserts and modifies. All we can determine is that the smaller the gap between the insert and modify, the more likely they are to be compressed.
Batching at different levels
Note that batching happens at both the Data Server and the update-queue level.
- Genesis batches on the queue level to minimize the amount of work the Data Server has to do. Because we pre-allocate LMDB when the data sever starts, having too many needless updates would eat into that allocation.
- Batching is performed on the Data Server to minimize the load on the client and the connection.
Out-of-sequence updates on the queue
Updates are published on the update queue once a record has been written to the database, or when a transaction completes.
Within a high-throughput set-up, where updates on the same table are published from multiple sources, updates can be received out of sequence.
This means that when listening to updates, in a high-throughput application, it is essential to check record timestamps to detect and handle out-of-sequence updates. For views, this is less of a problem, as Genesis refreshes the record from the database within a transaction to make sure that the published update is valid.
These multiple sources could be:
- Different event handlers on the same node modifying the same table
- The same event handler running on multiple nodes
Return Types
SyncEntityDb
The blocking - or sync - API is the simplest API for accessing the Genesis database.
Get operations in this API are nullable. When getting a record, you must check if it is null:
val trade: Trade? = db.get(Trade.byId("TRADE_1"))
if (trade == null) throw RuntimeException("Unable to find trade")
Write operations return either a single return object, or a list of result objects, for the ...All operations,
e.g. updateAll. These are never nullable.
val insert: InsertResult<Trade> = db.insert(trade)
val inserts: List<InsertResult<Trade>> = db.insertAll(myTrades)
getByCriteria, getRange and getBulk operations return a List<X>:
val trades: List<Trade> = db.getBulk(TRADE)
Note that this will load the entire table into memory. This is fine for smaller tables and ranges.
For large tables and ranges, the stream() function is provided on the database. This creates a Stream that streams the data, rather than loading it all in memory:
val trades: Stream<Trade> = db.stream().getBulk(TRADE)
try {
// use the stream here
} finally {
trades.close()
}
While this is more memory-efficient, the database connection will be kept open until the stream is closed. As in the above example, always close the stream. Not closing these streams will lead to your application running out of database connections.
AsyncEntityDb
The Genesis Application Platform relies on Kotlin coroutines for providing high-performance applications. The Async API is the preferred API for accessing the database in Kotlin. The RxJava API is also available. If you use Java, the asynchronous API is not available.
Coroutines overview
Coroutines provide support for non-blocking asynchronous operations at the language level. This makes the code highly efficient; it also means that asynchronous code can be written in a style that appears synchronous.
Traditionally, on the JVM, code waiting on an asynchronous operation will block a thread while waiting for completion or a result. For example, when waiting on the result of a Future, code will often call get, which will block the thread until the operation is completed.
Coroutines avoid this situation; they suspend, rather than block. When code reaches a point at which it can no longer complete and needs to wait for a result, it will suspend. It hands the thread back to the coroutine context, where it can be used by another call. Once the asynchronous operation completes, execution is resumed.
If you are not familiar with Kotlin coroutines, it is well worth finding out about them. They are very efficient. Both of the following are useful sources of information:
Using suspend
In Kotlin, a function modified with the suspend keyword becomes a suspending function. A suspend function can only be called from a coroutine. There are three types:
- Nullable suspend. This can only return a single value.
- Suspend. This can only return a single value.
- Flow. This can emit multiple values sequentially. A flow is conceptually a stream of data that can be computed asynchronously. The emitted values must be of the same type. For example, a
Flow<Int>is a flow that emits integer values.
RxEntityDb
RxJava is a Java implementation of reactive extensions. The Genesis database uses this library to represent asynchronous database operations in java.
If you are using Java. RxJava API is the only way of accessing the database. For Kotlin, the async API is preferred (although the RxJava API is also supported).
Subscription
It is important to note that any database operation with RxJava return type is cold until it is subscribed to. This means that the operation is not sent to the database until that time.
RxJava return types
The Genesis database uses three RxJava return types:
| Return type | minimum returns | maximum returns |
|---|---|---|
| Single | 1 | 1 |
| Maybe | 0 | 1 |
| Flowable | 0 | ∞ |
Single
In the RxJava API, a Single represents an asynchronous operation that has two possible outcomes:
- a success with result, or
- a failure
For example, on the database, delete returns a Single, with the following possible outcomes:
- the record was deleted; it provides a write result
- the operation was not successful; for example, the record was not found
Maybe
In the RxJava API, a Maybe represents an asynchronous operation that has three possible outcomes:
- a success with result
- a success with no result
- a failure
For example, on the database, get returns a Maybe, with the following possible outcomes:
- a record is found
- no record is found
- the operation was not successful, for example the index was incorrect
Flowable
In the RxJava API, a Flowable represents an asynchronous operation that has an undefined number of outputs.
Frequently asked questions
Write operations not updating in database
When using the RxJava api, it is paramount that you end the call chain with a subscribe... call. The underlying database operation will not commence until it is subscribed to.
Type Unsafe DB API
The following APIs for DbEntity and DbRecord are used rarely, when you need to operate outside the type-safety entities.
DbEntity
The DbEntity methods are described below:
| Name | Signature | Description |
|---|---|---|
| toDbRecord | fun toDbRecord(entity: E): DbRecord | Converts an entity to DbRecord |
| toGenesisSetFormatted | fun toGenesisSetFormatted(entity: E, configs: Collection<ColumnConfig>? = null): GenesisSet | Converts a view to GenesisSet and applies any formatter/aliases assigned to the fields |
| toGenesisSet | fun toGenesisSet(entity: E, columns: Collection<String>): GenesisSet | Converts a view to GenesisSet. This is the plain representation of view fields |
| get | operator fun get(field: String): Any? | Gets the provided field value |
DbRecord
Using DbRecord instead of entities will circumvent compile-time validation of database interactions. This means that errors might not appear until runtime or might lead to unexpected results.
DbRecord enables you to build a record of a specified table. It is not type-safe, so this is not our recommended method.
Constructors
| Signature | Description |
|---|---|
constructor(tableName: String) | Create record with specified table name. |
constructor(source: DbRecord?) | Clone existing record. |
constructor(targetTableName: String, source: DbRecord?) | Clone an existing record into another record belonging to a different table. This is useful when the target table record is the extended table of the source record. |
Example
val tradeRecord = DbRecord("TRADE")
val clonedTradeRecord = DbRecord(tradeRecord)
DbRecord("TRADE_SUMMARY", tradeRecord)
functions
Use the functions below to set and get fields of DbRecord. The field type can be any of these types.
Set record
fun set{DataType}(column: String, value: {DataType}?) You need to specify name and value of the column. DataType represents the type of the field you are trying to set.
If you are trying to set a Double field, the method would look like this: fun setDouble(column: String, value: Double?); the value needs to be non-null.
Get record
fun get{DataType}(column: String): {DataType}? You need to specify the name of the column. DataType represents the type of the field you are trying to get.
If you are trying to get a Double field, the method would look like this: fun getDouble(column: String): Double?, it returns value if present, otherwise null.
Generic getter and setter
fun getObject(column: String): Any? Generic access to fields. Returns value if present, otherwise null.
fun setObject(column: String, value: Any?) Generic setter for fields.
Other useful functions and properties
fun differenceInFields(comparatorRecord: DbRecord): Collection<String> This function compares the difference in fields between two records in the same table. It identifies the fields that have different values. Fields with the same values are ignored. If you try to compare fields from different tables, this returns an error.
Example
// gives the fields which differ in their values
dbRecord.differenceInFields(dbRecord2)
isEmpty This property identifies whether there is any content within the DbRecord. It returns true if there is no information collected within this record, otherwise, it returns false.
columns This property gets all columns for this record.
tableName This property gets the table name of record.
Timestamps
When you generate a database on the Genesis platform, every table in the database is given a TIMESTAMP and a RECORD_ID field.
- The
TIMESTAMPfield value is generated automatically by GenesisFlake every time a change is made to the database. - The
RECORD_IDfield is theTIMESTAMPvalue when the record is first created, it will never change.
The database generates a new TIMESTAMP for every modify operation, even if no other fields are changed.
To create these values, GenesisFlake generates IDs in a similar manner to Twitter’s snowflake. It is able to generate these IDs without having to perform database-level synchronization - which ensures high performance.
An ID includes:
- a node number (which represents the node id within a Genesis cluster)
- a sequence number (used to differentiate IDs generated within the same millisecond)
Timestamps are essential if you use Optimistic Concurrency.
Format
The GenesisFlake timestamp is made up of:
- epoch time in milliseconds
- node id
- sequence id
The timestamp itself is stored in the most significant bits of a LONG variable, leaving the least significant bits to node id and sequence number.
A raw ID value looks like this, for example: 6626101958220449352.
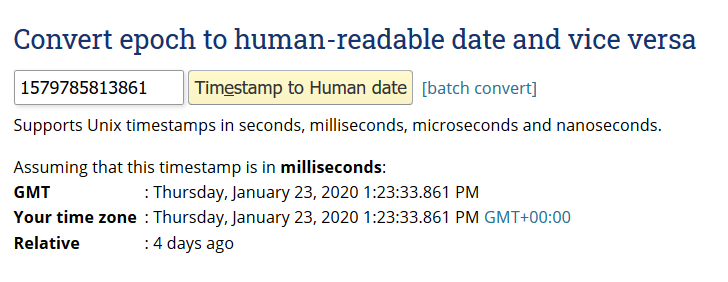
You can extract the timestamp component using bitwise right-shift operations. For example:
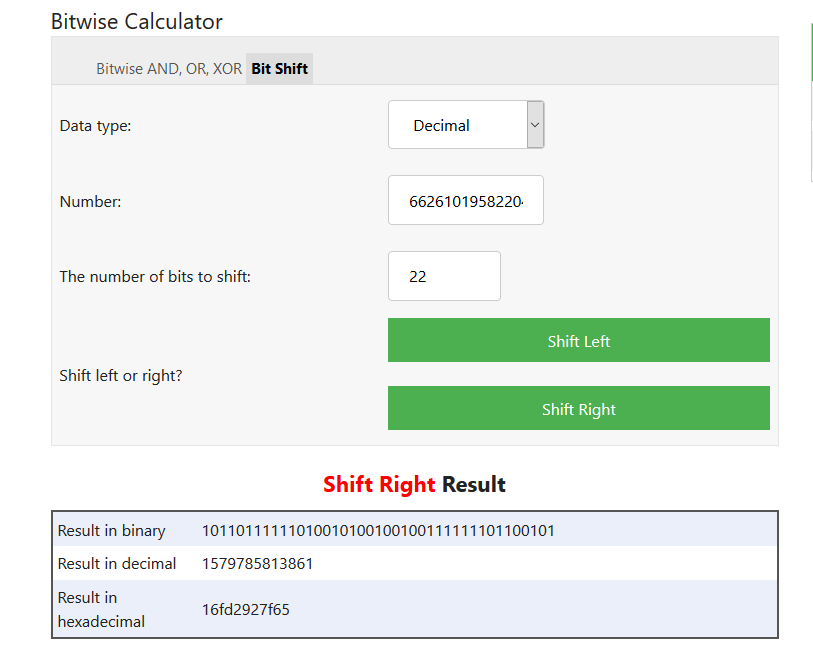
The result in decimal corresponds to 1579785813861, which can be checked in https://www.epochconverter.com/
Find most recent changes
To find the most recent change to table in your database:
- Add an index on the TIMESTAMP field for the table.
- Perform
a getRangeFromEndfor that index. This returns all the records, beginning with the most recent. - Keep only the first record.
Optimistic concurrency
Optimistic Concurrency helps prevent users from updating or deleting a stale version of a record. To do this, we need to know what the intended version of the record to update or delete is. Internally, we use the record's timestamp field as its version.
When enabled, the checks will be performed for each modify and delete operation on the configured tables. This could be when using the programmatic Genesis database API or on execution of an Event Handler.
Optimistic Concurrency can be configured with one of the following values: STRICT, LAX and NONE. These modes are detailed below. Defaults to NONE.
Modes
| Mode | Description |
|---|---|
STRICT | A check is performed on modify and delete database operations; the TIMESTAMP of the database record must be the same as the TIMESTAMP provided on the database operation. |
LAX | A check is performed on modify and delete database operations; if the database operation has provided a TIMESTAMP, the TIMESTAMP of the database record must be the same as the TIMESTAMP provided on the database operation. If no timestamp is provided, then no check is performed. |
NONE (Default) | Checks are disabled. |
Configuration
Optimistic concurrency can be configured using a global property that applies to all tables, or with table-specific properties that allow fine-grained control over individual tables.
Global configuration
There are two simple ways of setting the global property.
In this first example, we simply specify the global STRICT Optimistic Concurrency mode as one of the process options:
<process name="ALPHA_EVENT_HANDLER">
<groupId>ALPHA</groupId>
<start>true</start>
<options>-Xmx256m -DRedirectStreamsToLog=true -DXSD_VALIDATE=false -DDbOptimisticConcurrencyMode=STRICT</options>
<module>genesis-pal-eventhandler</module>
<package>global.genesis.eventhandler.pal</package>
<script>alpha-eventhandler.kts</script>
<description>Handles events</description>
<classpath>alpha-messages*,alpha-eventhandler*</classpath>
<language>pal</language>
</process>
You can also specify the global option using any of the other methods of defining system definition properties. In the example below, the configOverridesFile property is used, specifying a properties file alpha-sysdef.properties. Its content is shown in a separate codeblock.
<process name="ALPHA_EVENT_HANDLER">
<groupId>ALPHA</groupId>
<start>true</start>
<options>-Xmx256m -DRedirectStreamsToLog=true -DXSD_VALIDATE=false</options>
<module>genesis-pal-eventhandler</module>
<package>global.genesis.eventhandler.pal</package>
<script>alpha-eventhandler.kts</script>
<description>Handles events</description>
<classpath>alpha-messages*,alpha-eventhandler*</classpath>
<configOverridesFile>alpha-sysdef.properties</configOverridesFile>
<language>pal</language>
</process>
DbOptimisticConcurrencyMode=STRICT
Do not apply as a global system definition property, as some internal services cannot operate properly when this is enabled.
Table-specific configuration
In addition to the global configuration, you can also specify optimistic concurrency checks for specific tables. This allows you to have different concurrency modes for different tables within the same application.
To configure table-specific optimistic concurrency, use the DbOptimisticConcurrencyTable_ prefix followed by the table name. For example:
DbOptimisticConcurrencyMode=NONE
DbOptimisticConcurrencyTable_TRADE=STRICT
DbOptimisticConcurrencyTable_ORDER=LAX
DbOptimisticConcurrencyTable_SYSTEM_CONFIG=NONE
Table names in the configuration must match exactly with the table names defined in your data model. Invalid table names will cause a configuration error at startup.
Unlike the global DbOptimisticConcurrencyMode property, it is safe to specify table-specific properties as global system definition properties. These properties can be applied globally without affecting internal services that cannot operate properly with optimistic concurrency enabled as it will only affect the specified tables.
Configuration precedence
The optimistic concurrency configuration follows this precedence order:
- Table-specific configuration - If a table has a specific configuration (e.g
DbOptimisticConcurrencyTable_TRADE=STRICT), it will use that mode - Global configuration - If no table-specific configuration exists, the table will use the global mode (e.g
DbOptimisticConcurrencyMode=LAX)
For example, with this configuration:
DbOptimisticConcurrencyMode=STRICT
DbOptimisticConcurrencyTable_TRADE=LAX
DbOptimisticConcurrencyTable_SYSTEM_CONFIG=NONE
TRADEtable will useLAXmode (table-specific override)SYSTEM_CONFIGtable will useNONEmode (table-specific override)- All other tables will use
STRICTmode (global default)
Startup logging
When optimistic concurrency is enabled, the system will log the configuration at startup. This helps you verify that your configuration is being applied correctly. The logs will show:
- The global mode being used
- Which tables are configured for each mode (STRICT, LAX, NONE)
Example log output:
Optimistic concurrency check enabled. Configuration:
Global mode = STRICT
Strict tables = [TRADE, ORDER]
Lax tables = [INSTRUMENT, COUNTERPARTY]
None tables = [SYSTEM_CONFIG]
Example
Here's a practical example of how you might configure optimistic concurrency for a trading application:
# Global mode not set so default of NONE applies to all tables not specifically configured
# Critical trading tables - require strict concurrency checks
DbOptimisticConcurrencyTable_TRADE=STRICT
DbOptimisticConcurrencyTable_ORDER=STRICT
DbOptimisticConcurrencyTable_POSITION=STRICT
# Reference data tables - can use lax mode for flexibility
DbOptimisticConcurrencyTable_COUNTERPARTY=LAX
DbOptimisticConcurrencyTable_INSTRUMENT=LAX
This configuration ensures that:
- Critical trading data (TRADE, ORDER, POSITION) is protected with strict concurrency checks
- Reference data can be updated more flexibly with lax mode
- All other tables don't have unnecessary concurrency check overhead
Handling Errors
When an Optimistic Concurrency check fails, the system throws a GenesisDatabaseWriteException with the error code OPTIMISTIC_CONCURRENCY_ERROR. This exception contains a descriptive message explaining why the check failed.
Error Types
There are two main types of optimistic concurrency failures:
-
Record Changed Error:
"The database record has changed since the operation started."- This occurs when the TIMESTAMP in the database doesn't match the TIMESTAMP provided in the operation
- Indicates that another process has modified the record since it was last read
-
Missing Timestamp Error:
"Missing TIMESTAMP field."- This occurs when a STRICT mode is configured but no TIMESTAMP is provided in the operation
- Only applies to STRICT mode; LAX mode allows operations without timestamps
Example
Here is an example of how you can check for optimistic concurrency exceptions:
- Kotlin
- Java
suspend fun updateTradeQuantity(tradeId: String, newQuantity: Long) {
val trade = entityDb.get(Trade.byId(tradeId)) ?: run {
LOG.error("Trade not found for $tradeId")
return
}
trade.quantity = newQuantity
try {
entityDb.modify(trade)
} catch (e: GenesisDatabaseWriteException) {
if (e.errorCode == ErrorCode.OPTIMISTIC_CONCURRENCY_ERROR) {
LOG.error("Optimistic concurrency check failed for trade ${trade.tradeId}")
// Handle appropriately, retry operation etc
}
}
}
public void updateTradeQuantity(String tradeId, Long newQuantity) {
final var trade = entityDb.get(Trade.byId(tradeId)).blockingGet();
if (trade == null) {
LOG.error("Trade not found for " + tradeId);
return;
}
trade.setQuantity(newQuantity);
try {
entityDb.modify(trade).blockingGet();
} catch (GenesisDatabaseWriteException e) {
if (e.getErrorCode() == ErrorCode.OPTIMISTIC_CONCURRENCY_ERROR) {
LOG.error("Optimistic concurrency check failed for trade " + trade.getTradeId());
// Handle appropriately, retry operation etc
}
}
}
Best Practices
- Check the error code: Use
e.errorCode == ErrorCode.OPTIMISTIC_CONCURRENCY_ERRORin Kotlin ore.getErrorCode() == ErrorCode.OPTIMISTIC_CONCURRENCY_ERRORin Java to identify optimistic concurrency failures - Log appropriately: Log the error details for debugging and monitoring
- Handle gracefully: Decide whether to retry, fail gracefully, or implement alternative business logic based on your application's requirements
- Provide user feedback: When using in user-facing applications, provide clear messages about what happened
Event Handler
Optimistic Concurrency checks for Event Handlers are dependent on the availability of a timestamp field.
- You must make sure that any custom classes used in your Event Handlers have a timestamp field. Add this manually, if necessary. If there is no timestamp field, the database write will fail with an error stating that a TIMESTAMP field is missing.
- Generated entities always have a timestamp field, so the checks will work for these without any extra coding.
When optimistic concurrency checks fail in Event Handlers, they can be handled the same way as described in the Handling Errors section. If not handled, an error response will be returned to the caller of the event handler.
In this example eventHandler is called TRADE_MODIFY, and it is based on a generated entity.
eventHandler<Trade>(name = "TRADE_MODIFY") {
onCommit { event ->
val trade = event.details
entityDb.modify(trade)
ack()
}
}
Below is an eventHandler called TRADE_CANCEL. It is based on a custom class called TradeCancel, which itself is described in the second codeblock.
eventHandler<TradeCancel> {
onCommit { event ->
val message = event.details
val trade = Trade {
tradeStatus = TradeStatus.CANCELLED
}
trade.timestamp = message.timestamp
entityDb.modify(trade)
ack()
}
}
TradeCancel Kotlin data class
data class TradeCancel(
val tradeId: String,
val timestamp: Long,
)
Linking the front end
When sending an event to the server, the front end needs to know what timestamp to send as part of the payload.
The front end of Optimistic Concurrency is driven from Entity Management. You need to set up the relevant
Data Server query or Request Server requestReply for entity management.
Data Server
- If the
queryhas no specific fields defined, the checks work automatically. - If the
queryhas defined specific fields, you must add the TIMESTAMP field.
In this example, no specific fields have been defined:
query("ALL_TRADES", TRADE)
In this next example, specific fields have been defined, so we have added TIMESTAMP:
query("ALL_TRADES", TRADE) {
fields {
TRADE_ID
QUANTITY
PRICE
TIMESTAMP
}
}
Request Server
- If the
requestReplyhas no specific fields defined, the checks work automatically. - If the
requestReplyhas defined specific fields, you must add the TIMESTAMP field.
In this example, no specific fields have been defined:
requestReply(TRADE)
In this next example, specific fields have been defined, so we have added TIMESTAMP:
requestReply("TRADE", TRADE) {
request {
TRADE_ID
}
reply {
TRADE_ID
QUANTITY
PRICE
TIMESTAMP
}
}
Generated repositories
IMPORTANT!
Generate Repository usage is legacy. Entity DB APIs replace their usage. From GSF version 7.0.0 onwards, code generation for database repositories is disabled by default. To re-enable code generation, change the generateRepositories setting inside the build.gradle.kts files for the genesis-generated-dao and genesis-generated-view modules, as shown below:
codeGen {
generateRepositories = true
}
During the code generation phase, repository classes can be generated for every table and view in the system. These repositories provide a type-safe way of accessing the database.
The main differences between the generated repositories and the Entity Db are:
- The entity db can handle any database entity, each repository can only handle a single entity.
- The generated repositories have specific methods for every index of table/view, whereas the entity db is fully generic.
| Supports tables | ✔️ |
| Supports views | ✔️ |
| Supports any data type | ❌ |
| Class to import | [TableName]AsyncRepository \ [TableName]Rx3Repository |
| Type-safe read and write | ✔️ |
| Type-safe write result | ❌ |
| Returns data as | table or view entities |
| Writes data as | table entities |
| References indexes as | Generated methods |
| Programming interface | Async or RxJava |
| Write (input) | Generated |
| Write (output) | Write Result) |
| Subscribe | Record Update of entity type |
| Bulk or Range Subscribe | Bulk of entity type |
| Available in Event Handlers | ❌ |
| Available in custom Request Servers | ❌ |
With generated repositories, there are two flavours of the entity db:
-
one has a RxJava API signatures, for use from Java
-
the other flavour has an Async API signature, for use by Kotlin
If you have a table called POSITION, then, when you run a generateDao, two repositories will be generated: PositionRx3Repository and PositionAsyncRepository.
You can perform CRUD operations on Table/View by its primary key and indices.
Write result
This is a single catch-all type for results of a write operation when using generated repositories or RxDb.
This type has the following fields:
savedRecords- the saved recordsremovedRecords- the deleted recordsmodifiedFields- the updated fieldsnumRecordsDeleted- the number of records deletedisError- there was an error during the database operation. Needs to be checked whenValidationMode.LEGACYis usederrorText- the error description. Needs to be checked whenValidationMode.LEGACYis used
Modify details
ModifyDetails does the same job as EntityModifyDetails and takes similar arguments for use with RxDb.
Deadlocks in the database
Because of the asynchronous nature of the Genesis Database API, it can be tempting to make database calls while streaming data from the database. While this might appear elegant and memory efficient, for example:
db.getBulk<User>() // query A
.flatMap { db.get(UserAttribute.byUser(it.userName)) } // query B
.toList()
However, there is a serious risk of a deadlock while following this pattern. Query A will require a database connection, until it has consumed all data. Query B will require a database connection for every record in the USER table. If no connections are available for Query B, then Query A will never return or release its connection. This can eventually lead to all available connections being tied up.
In this case, the solution would be to use the USER_VIEW, which has data from both tables. In other cases it would mean collecting the data first, and querying after:
db.getBulk<UserView>()
.toList()
// or
val lookups = db.getBulk<User>()
.map { UserAttribute.byUser(it.userName) }
.toList()
val userAttributes = db.getAllAsList(lookups)
In addition to getBulk, this can also happen with getByCriteria and getRange.
To help with this, specifically when using a SQL database, Genesis offers help detecting deadlocks.
SQL Deadlock detection
The platform will monitor the available connections in the connection pool, and the time since a connection was last provided. If after a configurable threshold (10 seconds by default):
- no connection is available in the connection pool
- no connection has been provided within the threshold
The database will warn of a potential deadlock situation:
WARN global.genesis.db.engine.sql.utils.RxJdbcDataSource - No database connections available, last connection provided 10.802010372s ago
INFO global.genesis.clustersupport.availability.ProcessState - Setting process to WARNING. Database connection pool deadlock has been detected
This will also set the process status to WARNING.
The issue might resolve itself over time, in which case you will see:
INFO global.genesis.db.engine.sql.utils.RxJdbcDataSource - Connections once again available
INFO global.genesis.clustersupport.availability.ProcessState - Setting process to UP. Database connection pool is healthy
However, even if it resolves itself, this is very worrying and requires investigation.
Slow consuming query detection
In addition to the connection pool monitoring; the platform will also monitor query consumers. This will monitor the rate at which a query's records are being read. This also has a configurable timeout, which is 10 seconds by default. This timeout will be triggered if the consumer has not read a record within the threshold. At that point, the platform can either warn or cancel the query. If we warn, the query, slow as it might be, might have a chance to recover. If we cancel, we should be able to return the connection to the pool.
The warning will look like this in the log file:
WARN global.genesis.db.engine.sql.utils.RxJdbcDataSource - Slow Query detected, no data was consumed in 10s
Deadlock related system definition items:
These are the system definition properties related to deadlock detection:
item(name = "SqlConnectionDeadlockThresholdSeconds", value = "10")
item(name = "QueryReadTimeoutSeconds", value = "10")
item(name = "QueryCancelOnReadTimeout", value = "false")
For a full list of database related system definition properties see here